27. Mai 2012
Mappotino: A Robot for Exploration, Mapping, and Object Recognition
 How can we let a robot create a map of an unknown indoor environment using three cameras that simultaneously provide depth information and color images? We investigated this question in a four-week practical course at our university. This article sheds some light on the challenges involved.
How can we let a robot create a map of an unknown indoor environment using three cameras that simultaneously provide depth information and color images? We investigated this question in a four-week practical course at our university. This article sheds some light on the challenges involved.
Disasters are scenarios where a robot could be sent into an unknown environment for a search-and-rescue mission. Although we have not set out to create a robot that is deployable in a real disaster zone, we were keen on solving some of the challenges posed by such a setting.

The Mappotino robot and a room in the basement.
In our case, the mission of the robot (we named it Mappotino) was to autonomously navigate in the basement of our university building, a place with obstacles and narrow passageways. Thereby it needs create a 2D map of the basement while driving. The data collected by three combined depth+color cameras is then processed offline. The observations are used to compute a 3D model of the basement. Furthermore, the color images serve to recognize and locate targets.
On the hardware side, we equipped a standard Robotino platform by Festo Didactic with three Kinect cameras mounted on top of the robot, two computers, and a switch.
We have rid the Kinect cameras of their movable bases such that the cameras can be rigidly attached to the robot platform. Via USB, no two Kinect cameras can be connected to the same bus which reduced the choices on which computers the Kinect sensor data is read and processed. The two computers were equipped with a standard hard disk (no SSD) and less powerful than a common notebook, although one of the computers needed to be replaced by a notebook due to problems with the power supply. All computers, including the computer that is part of the standard Robotino platform were connected to each other using a switch.
Four weeks with such a variety of tasks leave little time for implementing every software component from scratch; therefore our choice fell upon the Robot Operating System (ROS) which not only provides an interface for controlling the actors and reading the sensors on the Robotino, but also software components for mapping, exploration, navigation, object recognition, and visualization. Unfortunately, the existing packages often proved insufficient in features or reliability, or were not tailored for our needs; hence we left none of them unchanged and even ended up implementing our own object detector for textured planar objects.
Most importantly, the robot needs to know about the obstacles in its vicinity. In order to achieve this, we wrote a fake laser-scanner that projects the 3D points acquired by all three Kinect cameras within the height of the robot onto the floor. The projections then – in principle – are inserted into the 2D map as obstacles (see image above). Since the odometry cannot be fully trusted, the series of such observations are merged into a grid-based map over time using the gmapping SLAM package from OpenSLAM.org.
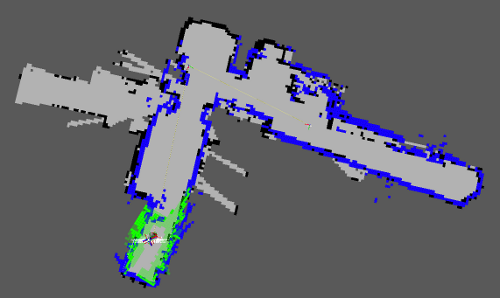
A generated 2D map, fake laser-scanner data, and obstacles.
For exploration, we tweaked an existing frontier-based ROS package (see: explore) for our purposes. Basically, given the current 2D map of the environment, the robot tries to find boundaries between unknown areas and known areas that are not obstructed by a wall.
For navigation, we adapted an existing ROS package (see: robotino_navigation). In theory, planning by finding shortest paths is straight-forward. Due to noise and uncertainty, this task turned out to be much harder in reality, especially given the narrow passageways our robot was to face in the basement.
The three Kinect cameras produce both depth images and color images, thereby accumulating massive amounts of data in the range of several Gigabytes. It already required significant efforts to improve the efficiency of existing packages to be able to write the data to disk. The post-processing of the data is done offline after the robot has finished exploration and mapping.
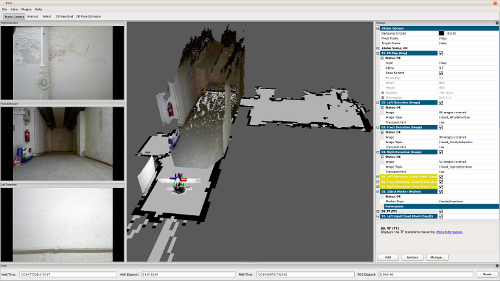
The Mappotino robot in action, visualized in RVIZ.
The collected data is used to compute 3D models of the environment and also to recognize and locate objects. Again, OpenSLAM.org came to the rescue with the RGBDSLAM package which merges 3D point clouds from multiple views into a common frame. Keypoints tracked in the images are used in order to compute the rigid transformation between two camera frames. This often fails when walls do not exhibit enough distinguishable features; in this case, RGBDSLAM will fall back to ICP, an iterative 3D point matching algorithm. We found the results to be good in rooms with many good features to track.

A 3D point cloud of the basement, stitched together with RGBDSLAM.
The Mappotino robot knows how to recognize objects and locate them in the environment. As we found none of those object detectors we were aware of to be sufficiently usable for our purpose, we ended up implementing our own detector for textured planar objects. We found a lot of promising features in existing object detectors, that is: RoboEarth, BLORT, and the detector shipped with ECTO but at the time of our practical course, these partly cutting-edge software components could not be integrated easily in a project that is bound to a certain software and hardware platform.
Our textured planar object detector (source) is based on matching local features learnt from a model image with local features from a scene image. The 3D data is completely ignored during recognition. Possible homographies between the model images and the scene images are suggested by RANSAC, and discarded depending on the number of inliers and the nature of the homography. The 3D location in the map is approximated by computing the 3D centroid; this requires the depth information from the Kinect camera.

The five target objects that need to be located.
All in all, this project taught us that ROS provides a lot of packages and very helpful tools in visualization. None of the packages could be used out-of-the-box; they needed adaptation to our platform, bug-fixes, installation tweaks, and much coding to meet our performance requirements. OpenCV has become powerful enough such that an object detector can be written on top of it almost without any other dependencies. See the robot in action .