18. Februar 2013
Computing PageRank for the Swedish Wikipedia
 Time to play search engine and experiment with PageRank. How much time does it take to page-rank a network with a million pages? I got curious during working on a university exercise and tested two power iteration variants and one Monte-Carlo method.
Time to play search engine and experiment with PageRank. How much time does it take to page-rank a network with a million pages? I got curious during working on a university exercise and tested two power iteration variants and one Monte-Carlo method.
Purpose of PageRank
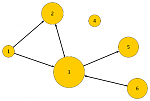
The PageRank algorithm, mostly known because of Google, assigns weights to pages in a web. The weights shall somehow represent the relative importance of pages within this web. There is a massive amount of information already available (e.g. [1], [2]). I will focus in this article on describing how the PageRank algorithm is connected to a vast number of areas of computer science and mathematics, and how three different experimental implementations performed on the Swedish Wikipedia. Here is an example web of altogether six pages, where the area denotes the PageRank:
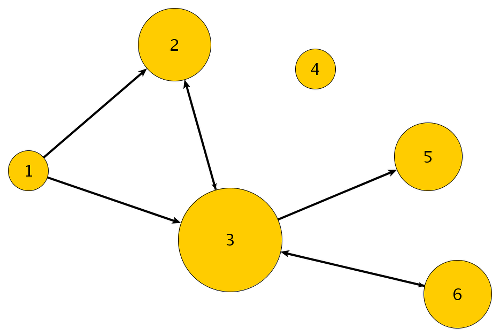
Swedish Wikipedia
The link structure of the Swedish Wikipedia was provided to me by the teachers of the university course DD2476 at KTH. The Swedish Wikipedia, at least at the time the link structure was recorded, comprises a million pages and is therefore large enough to be of interest, and small enough such that it can be handled in memory with a single notebook. Note that we have some intuition which Wikipedia articles should be highly-ranked, and which not. This is very convenient when assessing the computed PageRank results. There are 960726 pages in total, from which 32079 pages are sinks, i.e. pages that do not link to any other pages. We will see later that sinks pose a certain problem in PageRank computation.
Beautiful Theory
First and foremost, the PageRank algorithm is designed to solve a specific problem. However, the theory behind is surprisingly beautiful and the algorithm can be treated from different views. It connects at leasts statistics, linear algebra, numerical programming, and graph algorithms. The probably most intuitive access to the PageRank algorithm is provided by the random surfer model. From the random surfer, it is only a few steps towards formulating PageRank as an eigenvector problem for which a bunch of solvers are readily available.
Random Surfer Model
The PageRank value for a page can be interpreted as a probability. Take a web surfer who is visiting pages by clicking randomly on hyperlinks, and jumping to any page with a certain probability. Then the PageRank value is given by the probability of the web surfer visiting a page in the limit. This intuitive description of PageRank can be formalized with the help of Markov chains. The web can be seen as a Markov chain where pages correspond to states in the Markov chain a page, and state transitions correspond to hyperlinks. With a few modifications, the Markov chain is made ergodic and the unique stationary probability distribution yields the desired PageRank. Quite handy, because we can make full use of the existing tools for treating random walks with Markov chains. Here is the sample web again, arranged in a way that is more often used with Markov chains:

Monte-Carlo Simulation
Starting with the random surfer, proceeding with Markov chains, we end up with Monte-Carlo simulation as one possible way to compute the PageRank (see [3]). Basically, the idea is just to simulate the random surfer and keep statistics about how often the random surfer visits which page. Analysing this process theoretically is not exactly easy, but simulation the random surfer with a small computer program is not very difficult – sweet.
Probability Flow
Instead of simulating a single random surfer, we can reason about probabilities directly. The probability distribution of the page that the surfer is currently visiting changes over time. When we look at this probability distribution after long time (i.e. a large number of clicks), the initial distribution (i.e. the starting page) does not longer play a role, and the probability distribution converges to the stationary distribution – the desired PageRank vector.
Power Iteration
Computing the stationary distribution for a given Markov chain is equivalent to computing the left eigenvectors of the transition matrix. The transition matrix tells us the probabilities of jumping from one page to another, where the rows correspond to source pages and the columns to destination pages. Since we are only interested in the first eigenvector, it is convenient to use an iterative method such as power iteration.
Performance
In a few experiments, I compared three different PageRank implementations: two power iteration methods, and one Monte Carlo method. All three method were tested on the Swedish Wikipedia dataset comprising nearly a million pages.
The first method is plain vanilla power iteration, where we repeatedly apply the transition matrix to an initial PageRank vector. The program consists of a triple loop: the outer loop iterates until a certain level of convergence, the two inner loops perform the matrix vector product. Hence, the computational complexity is in O(K*N*N), where K is the number of iterations, and N is the number of pages. Time required: around twenty minutes.
The second method is also power iteration, but the effects of sinks in the network are approximated, which turns the quadratic term of the computational complexity effectively into a linear one at the expense of correctness. Usually, every page links only to a few other pages. This makes the transition matrix having mostly a sparse structure. However, since we are treating sinks in a network as if they were connected to all other pages, the transition matrix is not as sparse as we could wish. A heuristic therefore replaces the probability flow induced by sinks by a constant flow to all pages. Time required: about two seconds.
The third method is a Monte Carlo simulation as described in [3]. Here, we start a random walk from every page and keep statistics about the nodes we visited. The recorded statistics yield the PageRank vector. Time required: about one second.
Conclusion
PageRank connects to quite a number of different areas within computer science and mathematics. There are many ways to compute it and to look at it. The network layout with only a limited number of links from one page to another allows us to compute it in suprisingly little time.